Atomic
原子操作
use std::sync::atomic::{AtomicU64, Ordering}; use std::thread; use std::time::Instant; const LOOP_TIMES: u64 = 100000; const THREADS: usize = 10; // const 是编译时常量 不可变 static SAFE_COUNTER: AtomicU64 = AtomicU64::new(0); // static 程序整个生命周期 运行时初始化 可跨线程 fn main() { let start_time = Instant::now(); let mut handles = Vec::with_capacity(THREADS); // 创建10个线程 每个线程中循环10000次 每次对SAFE_COUNTER原子地增加1 for _ in 0..THREADS { handles.push( thread::spawn(move || { for _ in 0..LOOP_TIMES { // 原子地增加SAFE_COUNTER的值,并返回旧值 SAFE_COUNTER.fetch_add(1, Ordering::Relaxed); // Ordering::Relaxed: 最宽松的顺序,允许编译器和CPU进行优化(无限制) // Ordering::Acquire: 获取顺序,确保在获取操作之前的所有读操作都已完成 // Ordering::Release: 释放顺序,确保在释放操作之后的所有写操作都已完成 // Ordering::AcqRel: 获取释放顺序,读操作使用Acquire,写操作使用Release // Ordering::SeqCst: 顺序一致性,所有操作按全局顺序执行,最严格但性能最差 } }) ); } for handle in handles { handle.join().unwrap(); } println!("atomic运行耗时: {:?}", Instant::now() - start_time); println!("atomic: {} , {}", SAFE_COUNTER.load(Ordering::Relaxed), LOOP_TIMES * THREADS as u64); }
来对比下Mutex
use std::thread; use std::time::Instant; use std::sync::{Arc, Mutex}; const LOOP_TIMES: u64 = 100000; const THREADS: usize = 10; fn main() { let start_time = Instant::now(); let mut handles = Vec::with_capacity(THREADS); let counter = Arc::new(Mutex::new(0)); for _ in 0..THREADS { let _counter = Arc::clone(&counter); handles.push( thread::spawn(move || { // 在这里获取锁更好,但为了演示mutex与atomic的性能差异 将其放入for内部 for _ in 0..LOOP_TIMES { let mut counter = _counter.lock().unwrap(); // 获取锁 // ^^^^^^^^^^^^^^^^ 不推荐将锁放在这里获取 *counter += 1; } }) ); } for handle in handles { handle.join().unwrap(); } println!("mutex运行耗时: {:?}", Instant::now() - start_time); println!("mutex: {} , {}", *counter.lock().unwrap(), LOOP_TIMES * THREADS as u64); }
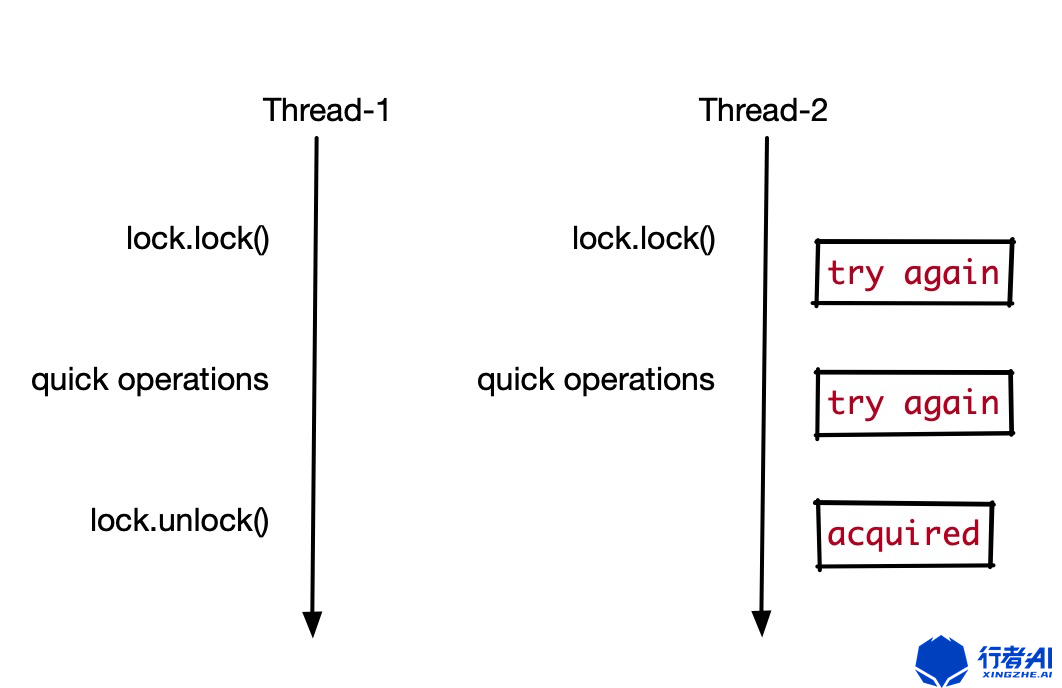
使用Atomic模拟自旋锁
use std::sync::atomic::{AtomicBool, Ordering}; use std::{hint, thread}; use std::thread::sleep; use std::time::{Duration}; use std::sync::{Arc}; fn main() { let lock = Arc::new(AtomicBool::new(true)); let lock_ = Arc::clone(&lock); let handle = thread::spawn(move || { sleep(Duration::from_millis(1000)); lock_.store(false, Ordering::SeqCst); println!("lock released"); }); println!("lock before"); // 自旋锁:不断检查counter的值,直到它变为false // 这是一种忙等待,会持续占用CPU while lock.load(Ordering::SeqCst) { // hint::spin_loop() 告诉CPU这是一个自旋循环,可以进行优化(如降低功耗) hint::spin_loop(); } println!("lock after"); handle.join().unwrap(); }
自旋锁的示意图: